Shape Analysis Group
Features matter! Geometry Feature Maps boost 3D recognition and detection. [1]
Convolutional neural networks (CNNs) have been dramatically successful in performing appearance-based object recognition tasks such as those in the ImageNet visual recognition challenge [A. Krizhevsky et al 2012].
In parallel, object recognition in 3D has drawn lots of research interest, in which however the backbone CNN framework is still a regular CNN on top of multiple feature maps derived from
2.5D point clouds [L. Bo 2013 and S. Gupta 2014]. The prior works differ in the way that they construct the input feature maps from given depth data and the core ideas are ad hoc. And the higher order gemetric features are
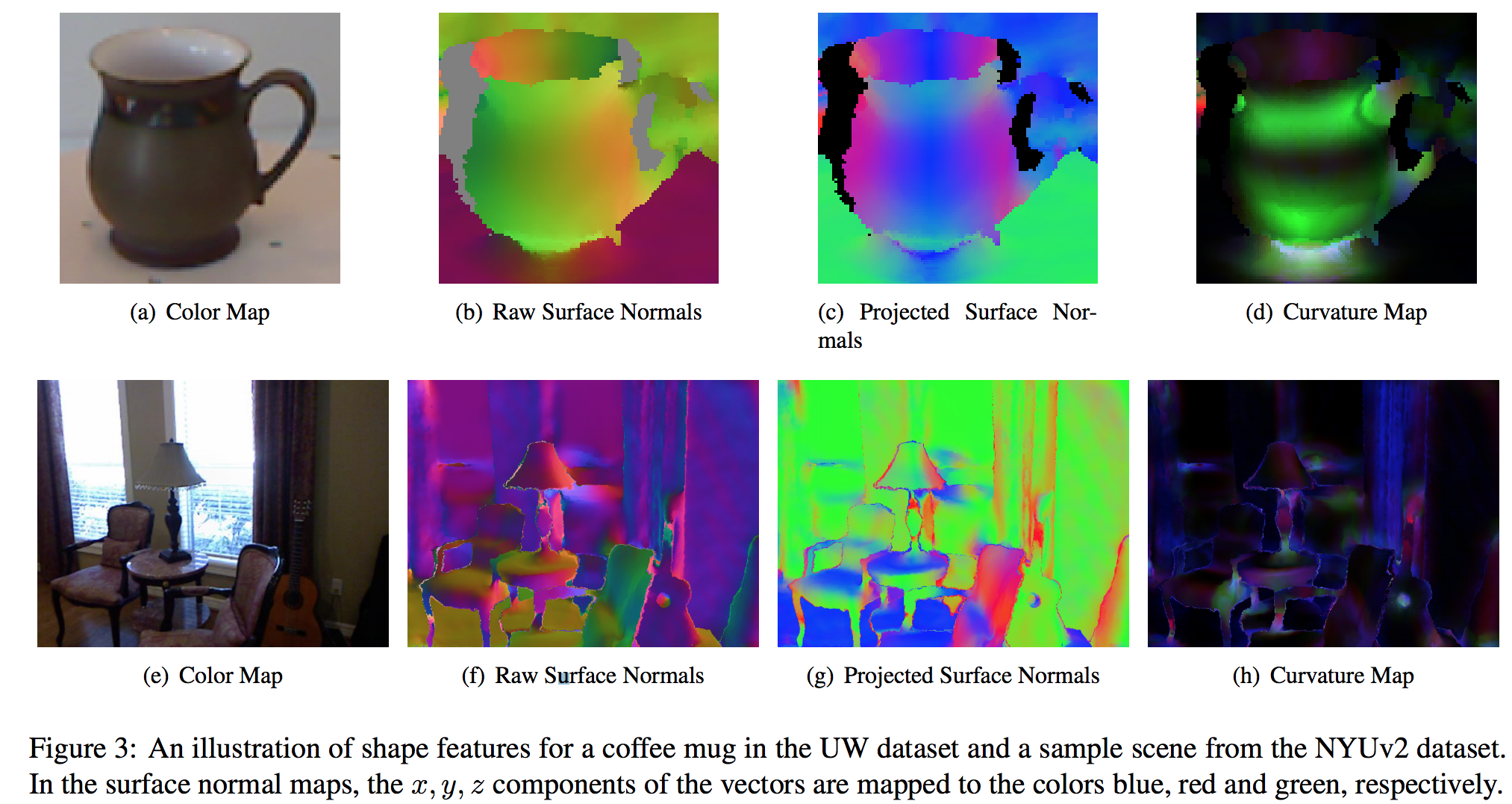
simply overlooked. In our work, we abstract surface geometry for 3D object detection in a principled manner, by using use zeroth order (depth), first-order (surface normal) and second-order (curvature) geometric information estimated from point
cloud data as inputs to CNN backbone in a RCNN framework [R Girshick 2013]. The geometry feature maps provided a non-trivial boost over prior state-of-the-arts on NYUv2 and UW RGBD dataset.
Combining Multiple Views for better global features. [2]
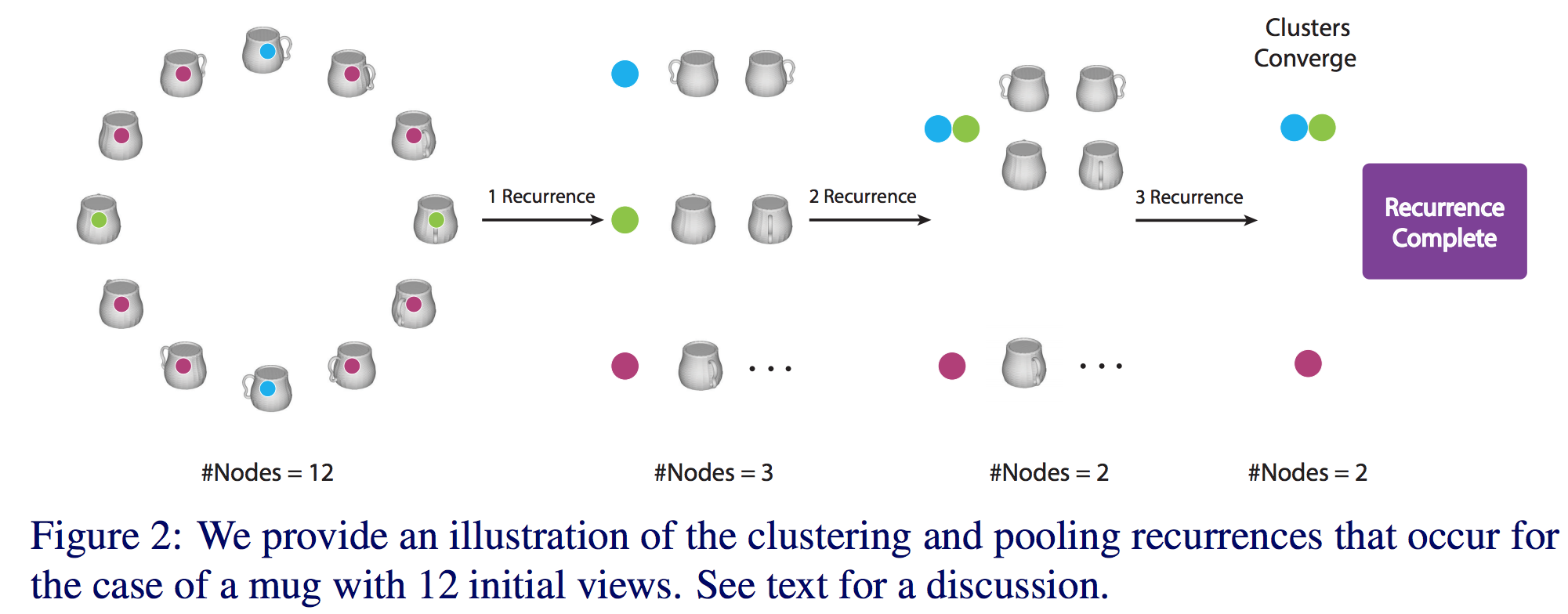
2.5D point clouds, which are essentially one single slice of the 3D object observed from a given view point, misses the global "big picture" of the object. A mug cannot be distinguished from another cylindrical object unless a handle-like structure is observed. This intuition leads to an idea of view pooling on CNN based features [MVCNN 2015]. Given multiple rotated views of an object as input, we feed them into a pretrained CNN and extract RELU features at its near to final layers, to serve as view descriptors. A max pooling is then applied on top of the individial feature dimensions to acquire a unified global feature descriptor of this object. In our work, we argue that the single max pooling ignores all other relevant view features except for the max, thus leads to low variance in the pooling output, which is non desirable for a descriminative task like object recongitnion. Instead, we propose to pool only within a group of "similar views", thus distinctive feature values does not get blended during the pooling operation which leads to higher information gain. We first apply dominant set clustering on a view graph whose nodes are views and edges encode pairwise similarity between different view (features). We then proceed to pooling only within each acquired cluster. We recursively apply the above process until convergence. Extensive experiments on ModelNet40 supports that the view based cluster pooling idea leads to better global feature descriptor of 3D object.
Graph CNN: towards structrual feature learning in point clouds [3]
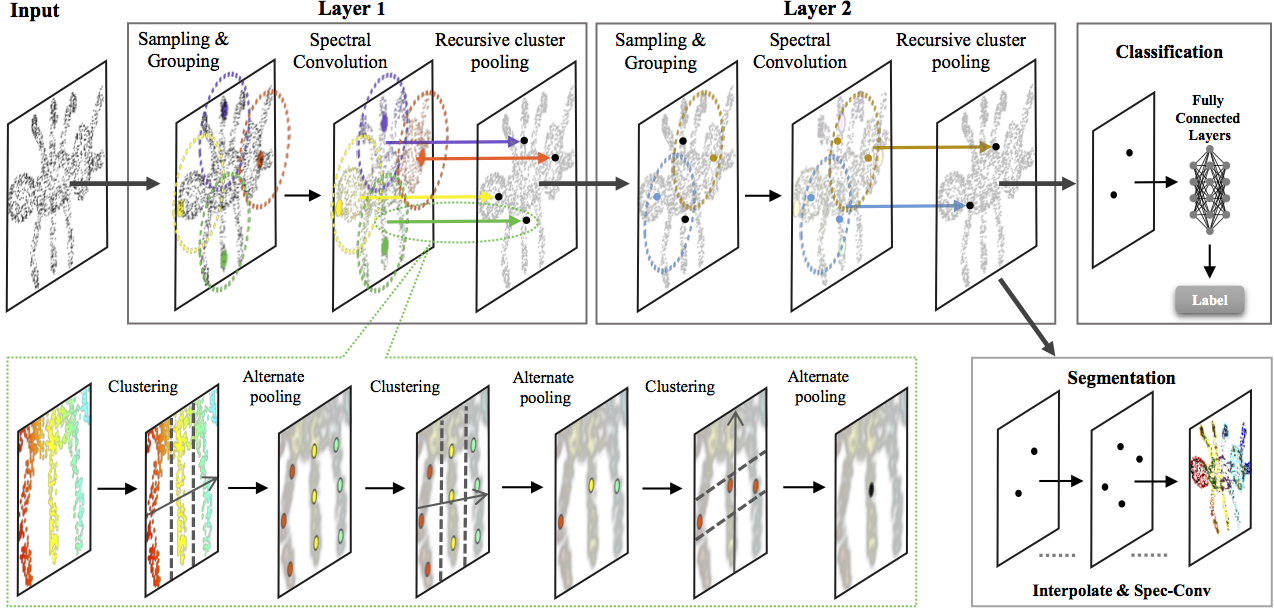
All the prior works, although claiming to solve the 3D vision problem, still relies on a 2D backbone CNN applied on either 2D feature maps for multiple rendered views. The proposal of pointnet and pointnet++ created an unified learning framework which directly operates on point cloud data, without reliance of rendering 3D into 2D. In a way, pointnet++ minics 2D CNNs in point clouds, where the challenge is you cannot naturally acquire a point neigbhorhood. Thus, pointnet++ first samples centroids in the point cloud, then finds nearest neighbors around each centroid, and finally perform feature abstraction in each grouped nearest neighbor balls. The core limitation of pointnet++
is that given a point neighborhood, the features are abstracted in an independent and isolated manner, ignoring the relative layout of neighboring points as well as their features. For each point, the spectral graph convolution output depends on all points in its neighborhood, whereas output from point-wise
MLP in pointnet++ only depends on the point itself.
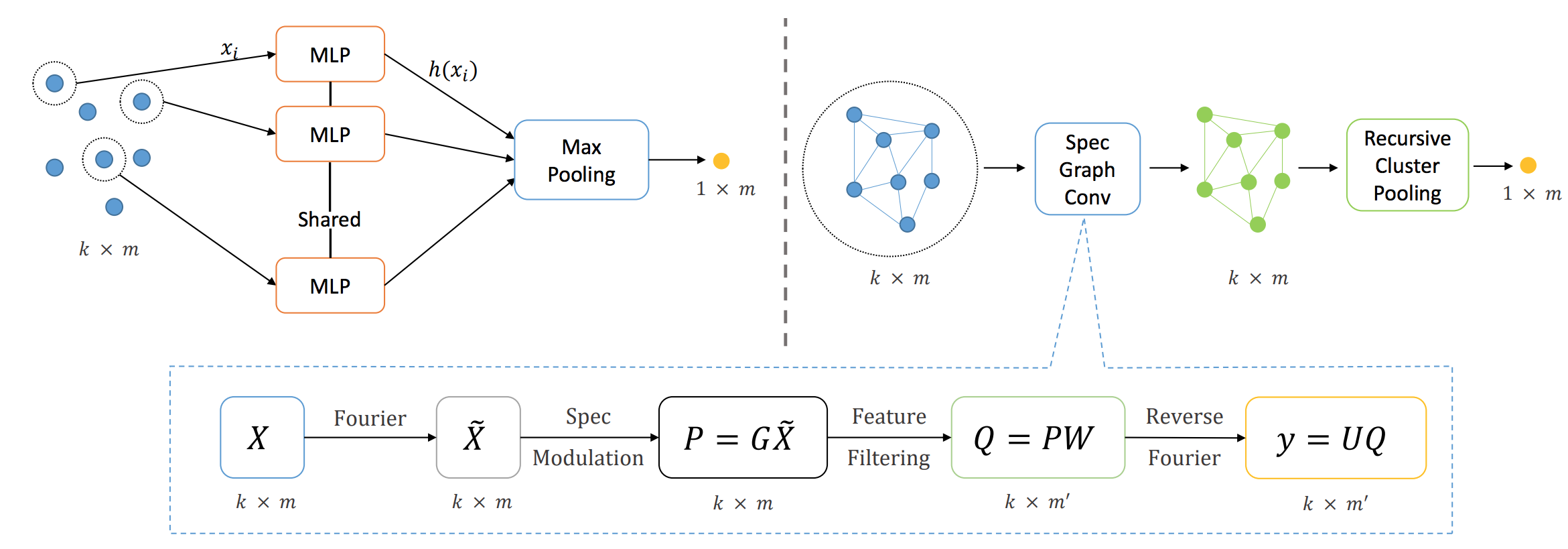
The key advantange of applying spectral graph CNNs in this task, is that the feature learning takes into account of the local point cloud structure. The intuition is, in spectral graph CNN, the point features got transformed into a graph Fourier domain, by expanding them to a basis of Eigenvectors, which is derived from the underlying graph. The transform is dependent on the graph laplacian, which is then dependent on the structure of the graph. After which, feature abstraction is carried on in Fourier domain, where the local geometry/structure is already incorporated. The advantage of local structural feature learning demonstrated a non-trivial boost over pointnet++, on multiple challenging datasets including McGill Shape Benchmark, MNIST, ModelNet40, ShapeNet Part Segmentation and ScanNet. We here present a teaser of the graph CNN based point cloud learning framework, with an example of an ant input.
Related Publications
[1] Chu Wang and Kaleem Siddiqi.Differential Geometry boosts Convolutional Neural Networks for Object Detection.
CVPR CVML workshop, 2016. [PDF] © 2016 IEEE.
[2] Chu Wang, Marcello Pelillo and Kaleem Siddiqi.
Dominant Set Clustering and Pooling for Multi-View 3D Object Recognition.
BMVC, 2017.
[PDF] [Code]
[3] Chu Wang, Babak Samari and Kaleem Siddiqi.
Local Spectral Graph Convolution for Point Set Feature Learning.
ECCV 2018. [Paper] [Code] © 2018 Springer.