Simulator to Robot Transfer
At the Mobile Robotics Laboratory, part of the Centre for Intelligent Machines and the NSERC Canadian network for Field Robotics, we are interested in designing robotic systems that can be deployed in the field to assist researchers for data collection and persistent monitoring tasks, with little human intervention. As part of this objective, we've been working on robot systems that can be programmed to perform tasks via composable behaviours: basic motor patterns that could be used in sequence to compute longer term plans.
To obtain such behaviours, we have experimented with designing and tuning controllers by hand with some success. However, we cannot expect these controllers to work in every situation the robotic system will encounter in the future; due, for example, to variations in the deployment environments and wearing of the robot components. Hence we turned to reinforcement learning, to synthesize controllers based on data gathered during robot deployments.
Learning behaviours from experience data
Prior work form our group, presented at ICRA 2015, demonstrated how such a system could synthesize controllers for a variety of behaviours on the AQUA swimming robot, based on the PILCO algorithm. To synthesize the controller for a new behaviour, we need to provide the robot agent with a score for how well it is performing the desired behaviour, a reward or cost function, and a controller for which we can tweak parameters to generate the behaviour, a policy that specifies which controls (e.g. motor torques) should be applied at any situation. Given the reward and the policy, one way to find good parameters for the policy is to repeat the following steps: 1) Execute the controller on the physical robot to gather new experience 2) Use the experience to compute the appropriate change in the parameters of the policy 3) Stop if no further improvement on the reward is possible.
This is roughly how we obtain the swimming behaviours shown in the video. To do so, we only need to specify the reward and policy and let the system do the search for the appropriate parameters. This is way more flexible than requiring a team of engineers to manually desgin and tune controllers by hand! However, we still need to deploy the robot in the field to gather new experience, which is not always easy to do.
Adapting learned behaviours to new environments
While PILCO aims to minimize the amount of real world experience data needed, it can still be a costly algorithm to run since: 1) With the current state of robotics, any field deployment carries considerable cost in terms of human labor, 2) Obtaining new experience requires the robot to execute exploratory actions in multiple novel scenarios, which carries the risk of damaging the robot and can be hazardous for humans around it, and 3) Most state of the art algorithms (such as PILCO) have high computational requirements leadding to long wait times between interactions with the robot system.
To deal with the aforementioned issues one should to try to avoid repeating work on the target robot as much as possible. One way to do this is to adapt controllers that have been learned on a source environment. The main idea is to first obtain policies in a surrogate, or source, enviroment which is less costly than the target one; e.g. a simulator, or a different robot, as illustrated in the following diagram.
We would like to desing a robot agent that can adapt to different environments and efficiently uses its experience to avoid learning from scratch
The only requirement is that the paths described by the robot system in the source are feasible in the target environment, even if the control signals are completely wrong; i.e. there exists a sequence of controls in the target environment that closely replicates the state transitions observed in the source environment.
With this assumption, we can then use the data from the target robot's experience to search for the controls that replicate the source behaviour. In our work, we propose to perform regression to obtain a predictor of the inverse dynamics of the system, i.e. a function that takes as input a sequence of states and outputs the next control that should be applied. Introducing the inverse dynamics between the soure and target domain could look like the following block diagram.
As a way to translate source behaviour to target behaviour, we could make use of an inverse dynamics model trained from data collected in the target domain
The inverse dynamics model can be used along with example trajectories from the source domain to generate a dataset of desired transitions and controls that realize them. Thus we could adapt any the source policy to the target environment by training, via supervised learrning, a policy adjustment model. We call it policy adjustment because it mmaps states and actions from the source domain into actions that produce the desired transitions in the target domain. The following diagram illustrates the policy adjustment model.
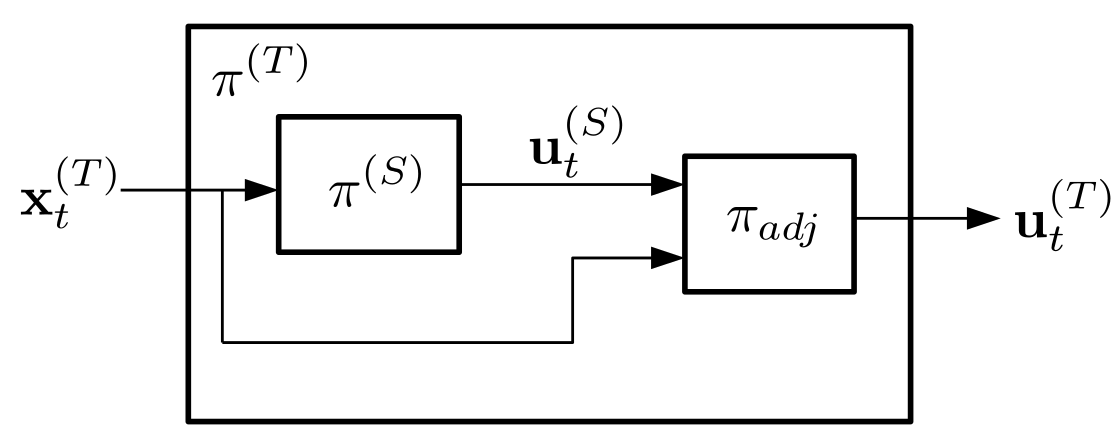
The policy adjustment model takes as input the state of the robot xt (T) and the control that would be produced by the source policy ut(S), and produces an action ut(T) that replicates the source environment behaviour
This idea is very similar to DAGGER, an imitation learning algorithm. The difference is that we don't query an expert for the controls that should be applied. Instead, we get example sequences of states from applying the policies on the source system, and search for the controls by solving for the inverse dynamics.
The following video demonstrates our idea on a cartpole system. We first trained the cartpole system to balance itself upright, using PILCO. Then we started modifying the system by changed the weight by 1.5x, 2x, 3x and 5x. Our algorithm was able to recover the original behaviour of the system in very few trials (between 2 and 5) and using a fraction of the computation time of PILCO. In the case of the 5x weight, the system failed to recover the original behaviour by the time we recorded the original video. But it did evetually find the appropriate controls after about 16 trials, still taking less computation time than PILCO (This work has been submitted to ICRA 2017 so more details to come soon. Wish us luck!)
Even though the algorithm seems to work, the assumption of feasibility of the paths from the source domain is a limited one. Soon we will be running some experiments with this algorithm on the AQUA robot, although I'm not sure if we should expect it to work. We are currently working ways to relax the requirement of feasibility and perhaps include a way to balance reward maximization with imitation of the source behaviours. Stay tuned!
Update (2017/01/15): This work will be presented at the 2017 International Conference on Robotics and Automation, ICRA 2017 in Singapore. You can downloadd the draft of the paper here. Hooray for robots!