a) [3 marks] Our algorithm for marking nodes of the parse tree with an asterisk (*), recursively marks those nodes, x, for which the subtree rooted at x denotes a query that can be assisted by the indexed fields. Express the criteria for which a node of the parse tree, T' should be marked.
1. if Q is of the form
2a. if Q is of the form (Q1 AND Q2 [AND Q3]) and the indices help
answer any of Q1, Q2 [, and Q3].
2b. if Q is of the form (Q1 OR Q2 [OR Q3]) and the indices help
answer all of Q1, Q2 [, and Q3]
b) [3 marks] Draw the parse tree, T', for the following query, Q, and mark all of the nodes according to the conditions you expressed in part (a). Assume that indices exist for the fields of MANUFACTURER and COLOUR.
Find the license plate numbers of all:
- the red cars manufactured by Ford in 1976, or
- the green cars manufactured by BMW, or
- the black cars manufactured in 1980 or 1981.
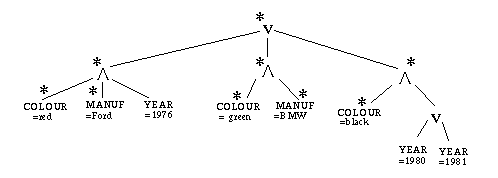
c) [1 mark] Do the indexed fields help answer the query, Q?
Since the root is marked, the indices help.
d) [5 marks] Write the general algorithm that obtains the set of records P(Q), satisfying a query, Q. Keep in mind that internal nodes may have either two or three children.
P(Q: query) : set of pointers
if Q is a leaf
then compute P(Q) directly using the index
else if Q is an AND node
let Q1, Q2, Q3 be the children of Q
if all three children are all marked
then P(Q) <- P(Q1) intersect P(Q2) intersect P(Q3)
else if two of the children are marked
let Q1, Q2 be the two marked children
P1 <- P(Q1) intersect P(Q2)
P(Q) <- {}
for each p element of P1
if record pointed to by p satisfies Q3
then P(Q) <- P(Q) U {p}
else (only one child is marked)
let Q1 be the marked child
P1 <- P(Q1)
P(Q) <- {}
for each p element of P1
if record pointed to by p satisfies Q2 and Q3
then P(Q) <- P(Q) U {p}
else (if Q is an OR node)
let Q1, Q2, Q3 be the children of Q
P(Q) <- P(Q1) U P(Q2) U P(Q3)
e) [3 marks] Assume that the car database consists of two files, with the following fields:
- AUTOMOBILE FILE: manufacturer, colour, license plate
- INSURANCE FILE: license plate, owner, year of manufacture
PI_ { [(sigma_ AUTO) |X| (sigma_ INSURANCE)] U
license MANUFACTURER = Ford YEAR=1976
COLOUR = red
[(sigma_ AUTO)] U
MANUFACTURER = BMW
COLOUR = green
{[(sigma_ AUTO)] |X|
COLOUR = black
[(sigma_ INSURANCE) U (sigma_ INSURANCE]} }
YEAR=1980 YEAR=1981
| Input ordering | internal sorting | replacement selection | natural selection |
|---|---|---|---|
| unsorted (random) (eg. F, D, A, R, ...) |
10 | 20 | 10e = 27 |
| sorted (eg. A, B, C, D, ...) |
10 | 100 | 100 |
| reverse sorted (eg. Z, Y, X, W, ...) |
10 | 10 | 10 |
| Iteration | File 1 | File 2 | File 3 | Total |
|---|---|---|---|---|
| n | 1 | 0 | 0 | 1 |
| n-1 | 0 | 1 | 1 | 2 |
| n-2 | 1 | 0 | 2 | 3 |
| n-3 | 3 | 2 | 0 | 5 |
| n-4 | 0 | 5 | 3 | 8 |
| n-5 | 5 | 0 | 8 | 13 |
Since we only have 10 actual partitions, we should distribute them as follows:
| File 1 | File 2 | File 3 | Total | |
|---|---|---|---|---|
| Real | 4 | 0 | 6 | 10 |
| Dummy | 1 | 0 | 2 | 3 |
| Total | 5 | 0 | 8 | 13 |
Non-linear probing causes synonyms (records whose keys hash to the same initial address) to trace out the same probing sequence.
b) [1 mark] Why does double hashing overcome secondary clustering?
Assuming a double hash function of the form p(K,i) = [h(K) + (i-1)h'(K)] mod M, even if h(K1) = h(K2), it is highly unlikely that h'(K1) = h'(K2). Thus, synonyms are unlikely to collide on the second probing attempt.
c) [3 marks] Is it possible to overcome secondary clustering with only a single hashing function? If so, provide such a function, and if not, explain why.
Yes, by combining the probe number term, i, with the key, k in a single function, for example, p(K,i) = [k × (k+i)²] mod M
An alternative, but not as general solution is to use a 1-1 mapping, such that the address space of the hashing function is the same as the key space. Naturally, this is not usually feasible.
Note that pseudo-random functions do not necessarily avoid secondary clustering.
Postscript files are in ASCII format. Furthermore, postscript previewers are readily available for most home computer systems.
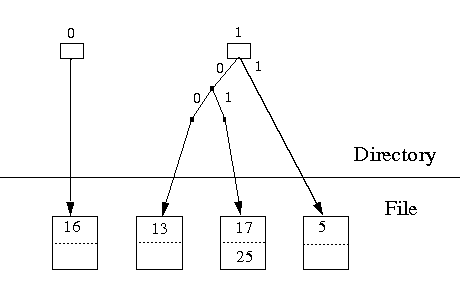
h(K) = K mod 4
and the first few bits of the B string associated with each key in
the file are given in the table below. Each bucket can hold up to 2
records. Show the state of the directory and the file after the records
with keys 17, 13, 16, 5, and 25 are inserted.
| Key | B |
|---|---|
| 17 | 01101 |
| 13 | 00101 |
| 16 | 10110 |
| 5 | 11110 |
| 25 | 01001 |
NS = M-1 × (KS + PS) + M × PS
= (10 - 1) × (10 + 4) + 10 × 4
= 9 × 14 + 10 × 4
= 126 + 40
= 166
b) [2 marks] Assume a B-tree consists of three levels of completely full nodes. You are asked to locate a particular record, with key K, followed by the next record in the sequence, and report its key value. Illustrate the best case and the worst case in terms of numbers of file accesses for this task. How many file accesses would be required in each case?
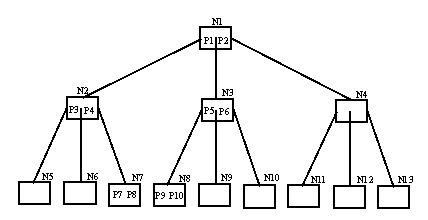
Best case: 3 file accesses. There are three possibilities, illustrated by the following examples:
a) The pointer P1 to the record with key K is found in the root node N1 and the pointer P9 to the next record is found in node N8.
b) The pointer P4 to the record with key K is found in node N2 and the pointer P7 to the next record is found in node N7.
c) The pointers P7 and P8 to both the record with key K and the next record are found in leaf node N7.
Worst case: 5 file accesses (or 3 if you are keeping a stack):
The pointer P8 to the record with key K is found in node N7 and the pointer P1 to the next record is found in the root node N1.
c) [2 marks] Assume instead that you were asked to perform the same task as from part (b) on a B+ tree with three levels of nodes. Illustrate the best case and the worst case, and provide the number of file accesses for each.
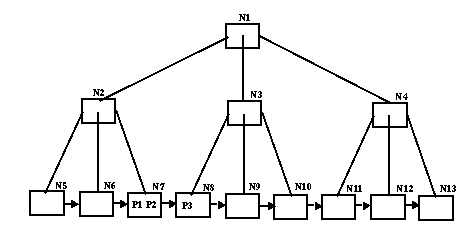
Best case: 3 file accesses. Since all of the pointers to main file records are stored in the leaf nodes, we must descend through the three levels of the B+ tree. At that time, we may find the pointers to both the record with key K and the next record in the same leaf node, for example, node N7, containing pointers P1 and P2.
Worst case: 4 file accesses: We find the pointer P2 to the record with key K at leaf node N7 and the pointer P3 to the next record in the right adjacent leaf node N8.
d) [3 marks] Assume that the B-tree nodes of part (a) are completely full. How many levels of index nodes would this B-tree require in order to store pointers to 10^4 (ten thousand) records?
The B-tree is of order M=10. So, assuming the root is level 0, a completely full level i of the tree contains pointers to 9 × 10^i records. The entire tree B-tree, m levels in height, consisting of completely full index nodes, must then contain pointers to the sum, from 0 to m, of 9 × 10^i records.
| Level | Record pointers in level | Total pointers |
|---|---|---|
| 0 | 9 | 9 |
| 1 | 90 | 99 |
| 2 | 900 | 999 |
| 3 | 9000 | 9999 |
| 4 | 90000 | 99999 |
Clearly, we require a minimum of four levels.